 中文
中文
 English
English 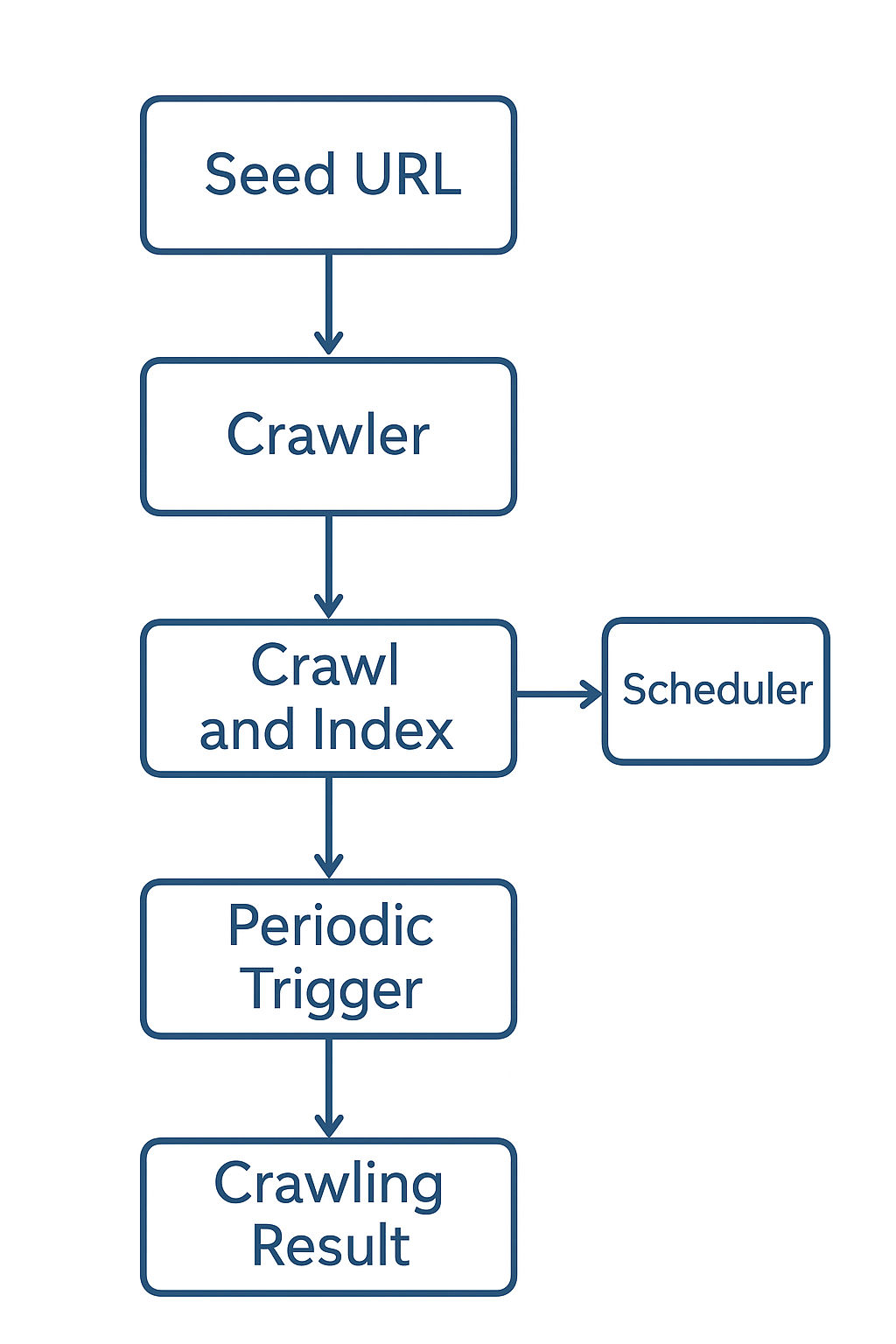
在网络数据抓取领域,很多人会选择手动编写爬虫脚本来抓取目标网站的数据。然而,YaCy 作为一个开源的去中心化搜索引擎,内置了功能强大的 自动爬虫和调度器,可以无需任何额外脚本就实现网站的定期抓取和索引。本文将详细介绍如何使用 YaCy 自动抓取网站,并进行周期调度。
一、YaCy 自动爬虫的核心功能
YaCy 的爬虫功能包括:
-
种子 URL 抓取
用户只需在控制台添加目标网站 URL(例如https://800188.com),YaCy 就会自动访问该网站并抓取页面内容。 -
抓取深度和页面数量控制
-
深度(Depth):控制爬虫从种子 URL 出发可以抓取的链接层级。
-
最大页面数(Max Pages):限制单次抓取的页面总量,避免服务器压力过大。
-
-
内容索引选项
YaCy 支持抓取网页文本和媒体内容,并将其建立索引,方便后续搜索和分析。 -
遵守 robots.txt 或强制抓取
默认情况下,YaCy 会遵守网站的 robots.txt 规则,但可以在调度器中设置强制抓取。
二、Scheduler(调度器):自动执行抓取任务
YaCy 内置的 Scheduler 可以让爬虫任务自动周期执行,无需手动启动。Scheduler 的核心概念包括:
-
动作接口函数(Action Interface):YaCy 内部定义的操作,如
crawlSeed、cleanDB、updateIndex等。 -
周期执行:可以设定任务每天、每周或每小时重复执行。
-
事件触发器:支持根据事件触发任务,但最常用的是定时执行。
Scheduler 使用步骤
-
打开 YaCy 控制台:
http://127.0.0.1:8090/ -
进入 Administration → Scheduler
-
点击 Add new task,选择动作
crawlSeed -
设置参数:
-
Seed URL:
https://800188.com -
Depth:3
-
Max Pages:500
-
-
设置周期执行:
-
Frequency:每天 / 每周 / 每小时
-
Start Time:第一次执行时间
-
-
保存任务并启用(Enable)
Scheduler 会自动调用 YaCy 内部 API,每到指定时间就启动爬取任务,同时更新索引。
三、YaCy API 与立即执行
除了周期调度,你也可以通过 YaCy 的内部 API 立即触发爬取任务,例如:
Invoke-WebRequest "http://127.0.0.1:8090/CrawlerAPI.xml?seedURL=https://www.800188.com&depth=3&maxPages=500"
注意:在 PowerShell 中,需要用双引号包裹 URL,否则
&符号会被解释为命令运算符。
四、总结
通过 YaCy,你可以轻松实现网站的自动抓取和索引,无需编写任何爬虫脚本:
-
配置种子 URL,即可抓取网站内容。
-
使用 Scheduler 设置周期任务,实现自动化抓取。
-
可结合 YaCy API 实现即时抓取或高级定制。
对于需要长期监控网站内容、建立搜索索引或进行数据分析的用户,YaCy 提供了一个零代码、可视化操作且功能完善的解决方案。
